AI-Powered Interview Prep
#1 AI Interview Prep App
Be Prepared, Be Confident – Interview Coaching for All.
Looking to prepare for a job interview? Huru is the #1 job AI interview prep app. Practice unlimited interviews and get immediate feedback with AI. Huru will help you prepare in an effective way to Improve your confidence and ace any interview. Get ready for the day of the interview!

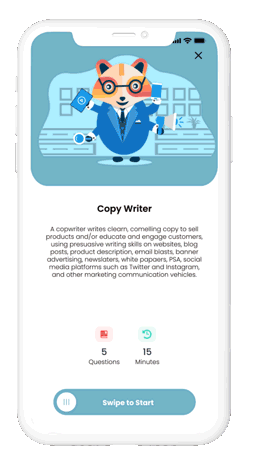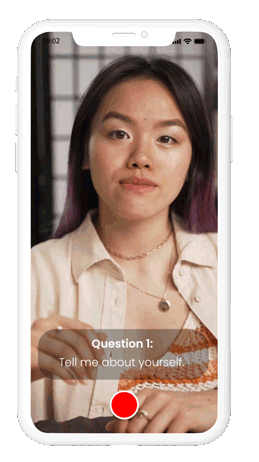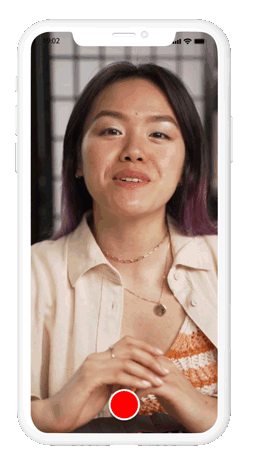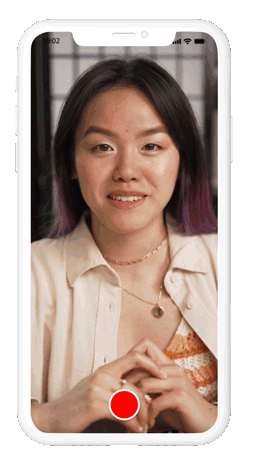

How to prepare for an interview with Huru?
1
Choose from any career position or from a job offer posted on popular job boards
Huru contains a large choice of interviews with different career professions.

2
Swipe to start answering interview questions
Its easy-to-use interface makes it convenient to conduct interviews.

3
Get immediate AI Feedback
Receive AI feedback on your answers, your speech, and receive advice on how to improve.

Easily practice interview questions from any job offer
Preparation is the key to get any job. Using our chrome extension, we automatically generate an interview from any job description posted on popular job boards such us Linkedin, Indeed, Glassdoor, ZipRecruiter and Monster. You can test your interview abilities and simulate the process itself by warping to the Qr-code.
Prepare for Any Career Position with +20K Mock Interviews
Get access to a wide range of mock interviews covering nearly every career occupation category in the employment market ranging from entry-level to executive positions and all in between. Questions are provided by Huru and are carefully handpicked by professional real-world hiring managers of big companies. You will be familiarised yourself with common interview questions and simulate in-person interviews.









AI Interview Preparation Coaching
Get powerful insight on how you perform. Get instant Feedback on your answers, Speech analysis, Answer tips to help you answer better.
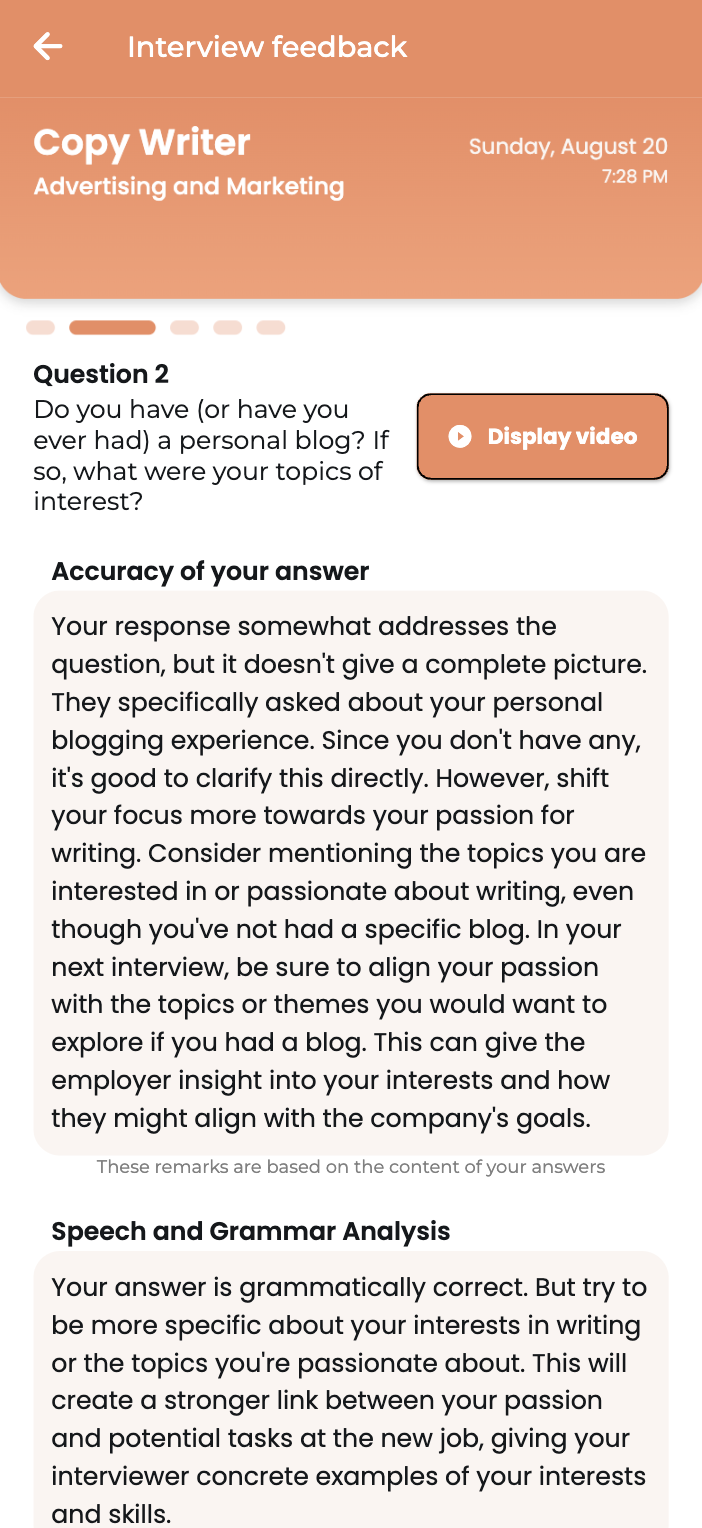
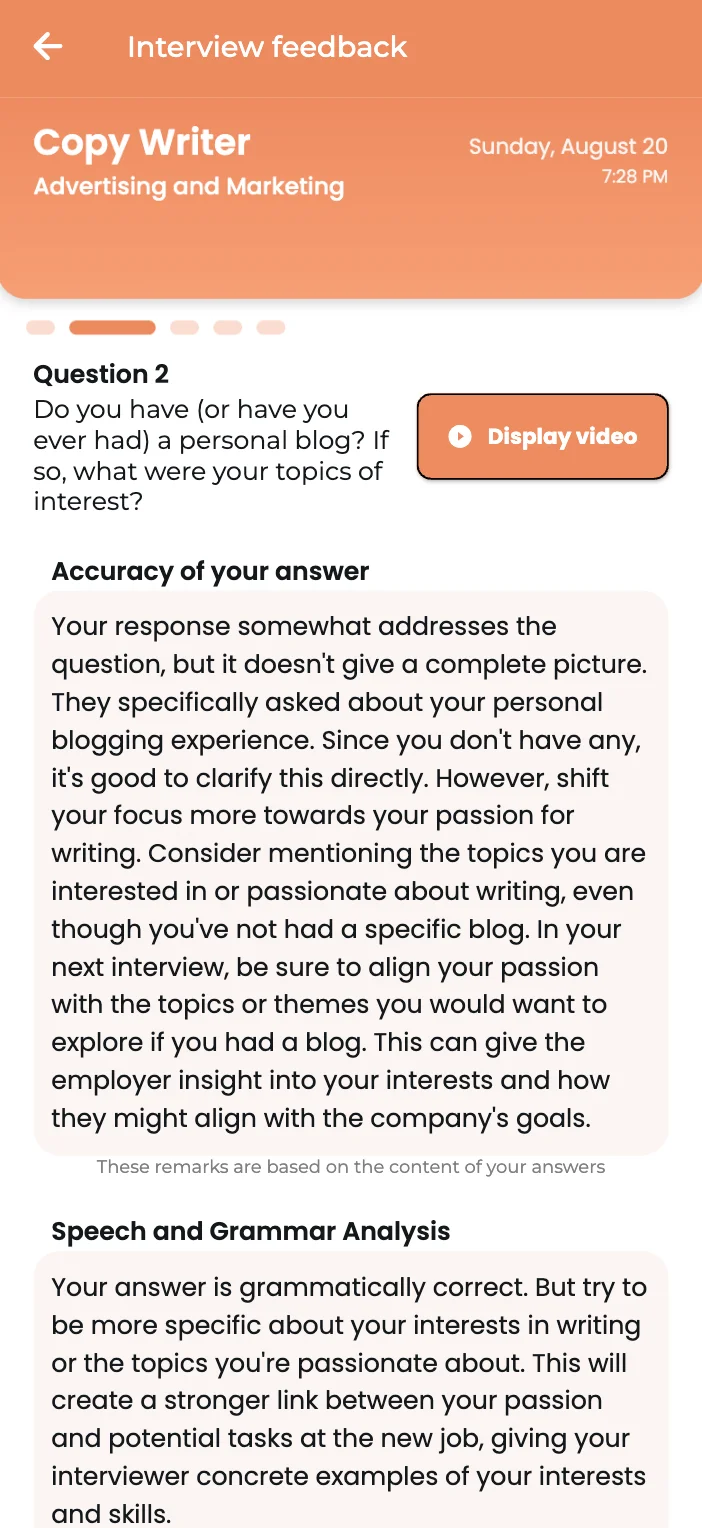
- AI Feedback
Get in-depth and immediate feedback
Boost your confidence by receiving instant feedback on your answers and learn from your mistakes during every interview. Our precise AI Feedback is at the core of ensuring a successful interview experience and be well prepared for your next job interview.
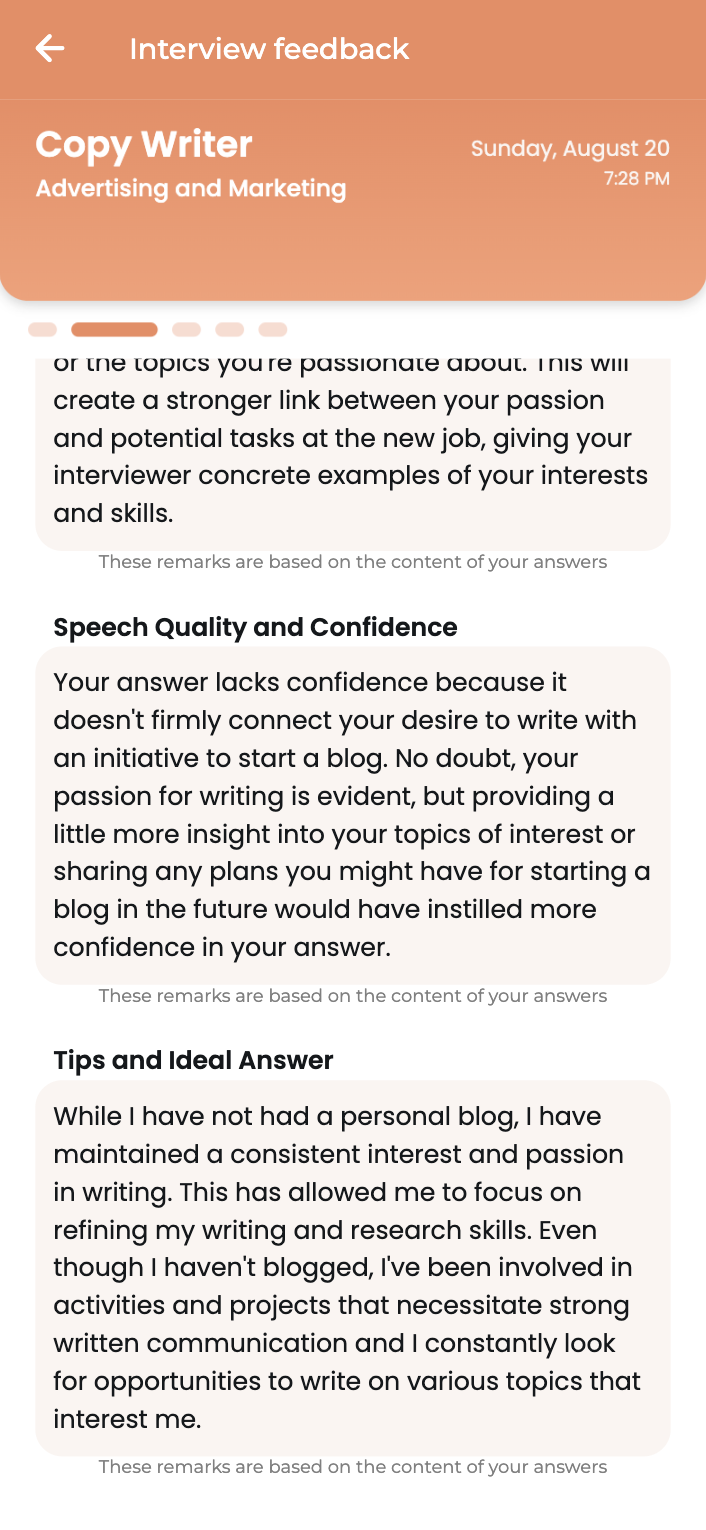
- AI Answer Tips
Get Answer Tips of every simulated interview
Huru provides interview tips for every question you’ll get asked like a know-it-all coach to structure well your interview answers. It will help you highlight your interview skills and make a good first impression in front of your recruiter. With this ultimate guide, you prepare your answers to help you feel confident.
Receive interview prep tips to impress your interviewer
Our newsletter help you keep up to date on the latest news and information about Huru. It can also help you stay informed about new updates, products or services that we offer. Join our email list to remain updated about Huru’s latest upgrades, news, and special offers.

Pricing
Unlimited practice interviews for confident job interview preparation. Increase your chances of landing your dream job.
We are dedicated to empowering individuals with the skills, confidence, and preparation needed to succeed in any interview. We believe that everyone, regardless of their background or experience level, has the potential to excel when given the right tools and guidance.
Our commitment is not just about getting you ready for the interview – it’s about building your confidence and showcasing your unique abilities. Because we believe that with preparation and belief in oneself, everyone can achieve their career goals. Be prepared, be confident – with us, it’s not just a slogan; it’s a promise.
Be Prepared at No Cost
- Unlimited interviews
- +20K mock interviews
- AI Feedback
- AI Answer tips
- AI Interview generation from any job offer listed on popular job boards (LinkedIn, Indeed, ZipRecruiter, Glassdoor, Monster)
Web Access:
Mobile App:
OR SCAN THIS QR CODE
Don’t hesitate! Your act of sharing Huru could be a game-changer for those in need of similar support and guidance, making it easier for them to discover this valuable resource.
Avoid stress and negative feelings, Improve confidence and be comfortable when meeting any interviewer. Don’t miss opportunities. Reach your full potential. Using Huru, users can focus only on their performance. Interview questions are generated automatically and gives you all the tools you need to succeed and help you ace your interview.
Powerful job interview preparation features.
Be ready to answer any question with confidence.

Frequently Asked Questions
Have questions? We’ve answers. If you can’t find what you are looking for, feel free to get in touch.
Is Huru just another generic interview question bank?
Nope! Huru’s AI personalizes your experience by learning your strengths and weaknesses, crafting dynamic interview scenarios, and offering tailored feedback.
Will Huru make me sound like a robot?
Fear not! Our AI is designed to simulate human conversation, helping you develop natural responses that showcase your personality.
I sweat bullets during interviews! Can Huru help with my anxiety?
Absolutely! Huru’s unlimited practice sessions allow you to build confidence and overcome interview jitters by familiarizing yourself with the interview environment.
Can Huru help me negotiate my salary?
While Huru doesn’t directly negotiate your salary, our interview prep can boost your confidence and communication skills, making you a more persuasive candidate when it comes to salary discussions. Additionally, by helping you land your dream job, Huru opens the door to potentially higher-paying positions.
What operating systems does Huru support?
What languages that Huru support?
Huru supports English, Spanish, German, Portuguese, French.
Other languages coming soon.
Who is Huru for?
Huru is designed to help everyone including candidates, students to ace their next interview (in-person, Video or phone interview) and to improve their communication skills. No more preparations in front of a mirror, Huru simulates interviews for you and record your answers and make you review your videos anywhere, anytime.
How can I use Huru to prepare for a job offer already listed on Linkedin?
Yes, effectively. Our google chrome extension allows you to generate interview questions from jobs listing on Linkedin, Indeed, Monster, Glassdoor, ZipRecruiter and soon Handshake. So, you can practice from the App and get instant feedback. Also you can practice with new questions in every interview or re-take previous ones.
When do I expect to see improvements?
Seeing improvements depends on how often you practice interviews. The more you practice, the faster you will see results and will give you abilities to ace any upcoming interview. Practicing interviews gives you experience in how to answer questions. Practicing will improve your abilities to think through questions, and you will have a better understanding of how to talk about yourself and your experiences. Practicing also helps with interview nerves. The more you practice, the more confident you will feel in your answers and in your ability to sell yourself.
Land Your Dream Job with Huru: Here's How!
Feeling anxious about your next interview? You’re not alone. But what if you could practice with a realistic AI interviewer, get personalized feedback, and walk into the room feeling confident and prepared? That’s exactly what Huru offers. Here’s how using Huru can significantly boost your chances of landing your dream job:
- Increase Your Hireability by 67%: Studies show that Huru users are 67% more likely to get hired compared to those who don’t use interview prep tools. This is because Huru helps you refine your interview skills, making a strong and confident impression on employers.
- Master Any Interview: Practice with a vast library of interview questions tailored to over 2000 job roles. Whether it’s a technical interview for a software engineer position or a behavioral interview for a marketing role, Huru will prepare you for the specific challenges you’ll face.
- Get Personalized Feedback: Our advanced AI analyzes your answers and provides insightful feedback on things like clarity, delivery, and confidence. This personalized guidance helps you identify areas for improvement and refine your responses for maximum impact.
- Build Confidence Through Repetition: Practice makes perfect! With Huru, you can conduct unlimited mock interviews, allowing you to hone your responses, manage interview anxiety, and feel completely prepared on the big day.
Don’t settle for anything less than your dream job. Download Huru today and take control of your interview success!
Good Luck for your next interview!